Data science at Coalition: Building real-time feature computation with Snowflake + DBT


Coalition is a technology (and data) company at heart and an insurance company by trade. Our engineering, data, and product teams are constantly innovating. This is a brief analysis of how the data science team utilized Snowflake and DBT to attempt to answer the question all insurance companies face: how do we reliably predict the likelihood of winning new clients?
Introduction to the problem
In insurance, multiple insurance providers compete with each other on price and coverage to win a prospective client's business. Market conditions can change quickly, especially within specific industries. Accurately estimating our probability of winning any given deal is useful for a wide variety of analyses, but updating features' reliability can be tricky. How should we build such a system?
Engineering implementation
From an implementation perspective, the system that computes “probability to buy” scores would ideally have the following attributes:
Continuously updated features: If last week, restaurants were unlikely to buy from us, but this week they are more likely, we’d like to reflect that immediately in our probability estimates.
Auditable: We want to be able to re-create all probability estimates. If we gave a business a 20% probability to buy last week, and this week gave the same business a 30% probability of buying, we want to be able to deconstruct that +10% delta into its constituent inputs.
Low infrastructure footprint: We want data scientists to be able to run and tweak this system full-stack without a large burden on SRE/platform engineering support. The more that data scientists can own the problem end-to-end, the faster they will be able to iterate.
Is this one of those “good, fast, or easy, pick two” scenarios?
Creating a feature warehouse
Fortunately, we’ve had success using Snowflake, a scalable data warehouse, and DBT, an analytics engineering tool, to help build and run this system. DBT calculates the features in a consistent manner for offline/online usage, and their snapshot functionality allows us to recreate any past prediction, if necessary. Snowflake allows us to run the whole system with a dedicated worker (warehouse), so data scientists can access the data without affecting the online model performance.
The entire setup is best illustrated in the following diagram:
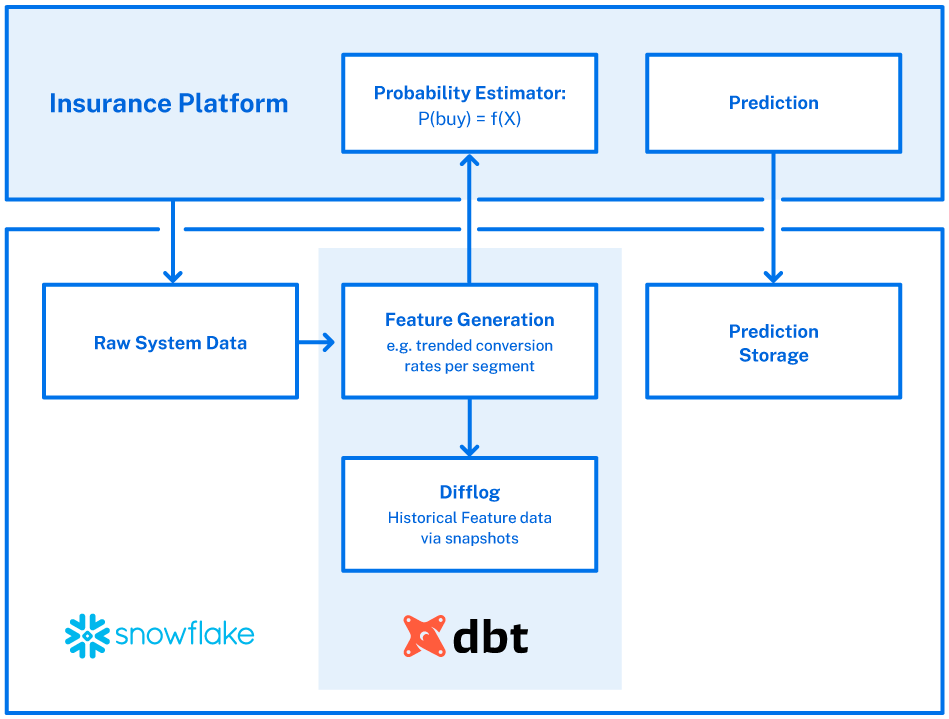
We’ve had this system running for over a month now and have been pleasantly surprised at how easy it was to set up and maintain. A common anecdote is “Data Science is 80% data cleaning and engineering, and 20% modeling,” but this lightweight approach has allowed us to focus most of our effort on the specific form of the probability estimator. We call that a success.
Always room for improvement
As always, no system is perfect. We see two potential areas for future improvement:
We could add an additional DBT job
that takes the prediction outputs, compares it with actuals, and creates a calibration table to help us understand the performance of the model automatically.
We could even use DBT’s monitoring and alerting features
to alert us when probability calibration performance degrades beyond acceptable limits.
If these types of challenges sound interesting, or you’d like to learn more about data science at Coalition, visit our careers page for more information and open opportunities
Related blog posts

Blog
After Mythos: What Actually Changes for Cyber Risk
Why the sky isn't falling, where the threat surface genuinely expands, and why point-in-time cyber underwriting is running out of road.


Blog
Active Insurance is Built to Dominate the AI Risk Landscape
While much of the insurance industry treats AI as a terrifying, unquantifiable specter, Coalition policies have always been designed to respond to AI risks.

Blog
5 Essential Insights From Our 2026 Cyber Claims Report
Discover how Active Insurance is helping businesses overcome the Cyber Protection Paradox with insights from Coalition’s 2026 Cyber Claims Report.
