
Cyber insurance and data - Part 1


In the first part of what will be a series of posts, we will talk about what we are currently doing and what we will do in the future to improve the cybersecurity of Coalition policyholders.
At Coalition, data is a big part of what we do. Data tells us the state of policyholders' risk exposure, tells us potential vectors of attack when a claim is filed, and shows us trends and accumulation in our book. Data is a large part of our DNA.
As detailed recently, Coalition acquired BinaryEdge, an internet security data scanner. Today, we wanted to give you a bit of insight into how Coalition policyholders are benefitting from this acquisition.
BinaryEdge recently released a group of new "web scanning modules".
These new modules revamp how we do HTTP scanning and also allow us to identify and extract metadata from a group of technologies, more specifically:
WordPress
Drupal
Joomla
Umbraco
Magento
Citrix ADC (formerly NetScaler)
F5 BIG-IP
Any new module released in the BinaryEdge platform immediately provides Coalition with new insights into our policyholders' (old and new) exposure.
The reason for that is because we have a continuous enumeration and scanning process that we run against any new and active policyholders. It looks like this:
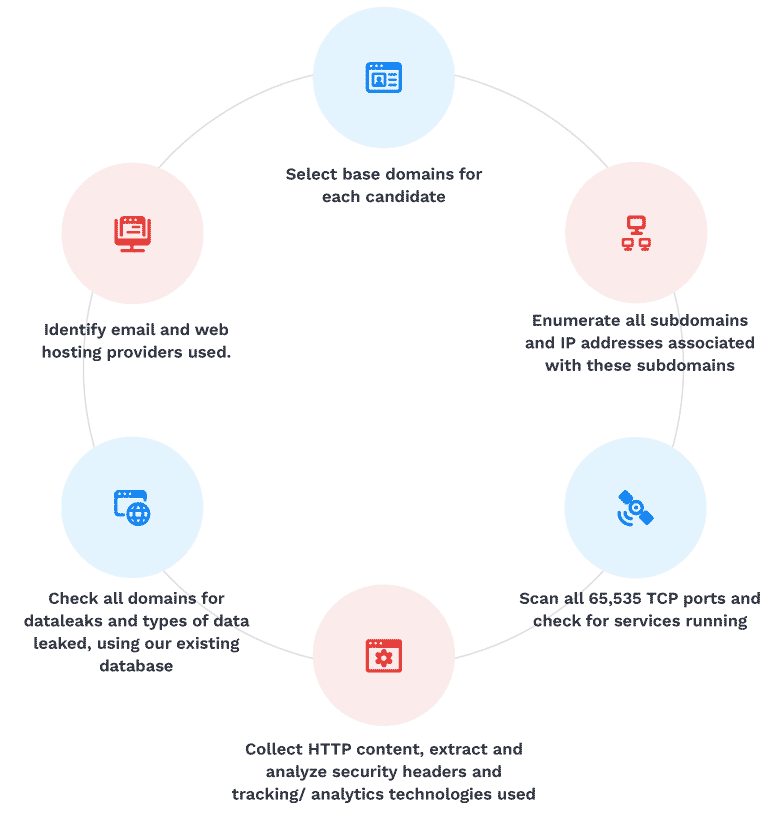
Looking at the following graph we can see that some policyholders (orange dots) have one or sometimes two of these technologies (blue dots).

The main cluster is WordPress. As one of the most used blogging and website technologies, this is expected. Having a graph with different relationships and dependencies makes it easier to understand when there are multiple dependencies (one policyholder having more than one technology) or accumulation (multiple policyholders using one technology).
This type of information is important to know. When a new vulnerability is released, we have a quick view into how many policyholders are potentially affected and need notification.
However, these web technologies are just one data point in a large universe of data that is made of multiple different views and levels, which we leverage fully to protect our policyholders and across the entire insurance chain.

Other datapoints we use include:
Ports open
Services running
Dataleaks
Sensor data
Malware infections
Torrent downloads
Acquisitions/Subsidiaries
Industry
Revenue
And much more.
At this moment, every new and current policyholder is regularly scanned and continuously notified of mis-configured and vulnerable services at no extra cost.
We are working to make even more of this data visible to policyholders at the appropriate level of detail. This is something we will discuss in future posts.
For cybersecurity to be successful, a good collaboration between insurer and policyholder is a key factor.
In the next blog post we will go deeper into our continuous scanning and notification process!
Related blog posts

Blog
Canvas and the Expanding Blast Radius of Cyber Attacks
The Canvas breach is a reminder that modern organizations are increasingly interconnected through shared technology dependencies that cut across industries.


Blog
Bank Impersonation: The New Frontier of Funds Transfer Fraud
Bank impersonation is on the rise. Discover why these new social engineering scams make it harder to recover stolen funds and how to protect against them.


Blog
Introducing Enhanced Business Recovery
Enhanced Business Recovery is a suite of endorsements designed to protect revenue, speed up settlements, and keep businesses running while claims are processed.
