
Thinking about “context” for web assets: Automating attack surface tagging and classification for scale

This research and article was written by Colin Flaherty as part of a summer internship with assistance from some of the team at Coalition: Beatriz Lacerda (Data Scientist), Florentino Bexiga (EM Data Collections) and Tiago Henriques (GM Customer Security).
Introduction to the problem
Assets can either be identified as domains or IP addresses. A single domain can point to multiple IP addresses, and multiple domains can point to a single IP address. Assets are assigned vulnerability scores through a slew of heuristic methods, discussion of which is beyond the scope of this article. If multiple assets have the same vulnerability score, how can one prioritize which of these assets to examine first?
For example, a login page without SSL is probably more important to address than a static blog post without SSL. One way to prioritize assets that have the same or similar vulnerability scores is by assigning them comparable “contexts” that encapsulate information about how sensitive or otherwise important they might be. One attempt to tackle this problem is “Eyeballer," an open-source machine learning project that uses a convolutional neural network to assign tags to webpage screenshots such as “homepage,” “custom 404,” “login,” and “old-looking.”
For the purposes of this article, I focus on contextualizing HTTP/HTTPS assets, i.e. web pages.
High-level approach
Contexts should be comparable because they will be used to compare assets. Therefore, structured contexts should be favored over free-form contexts. For example, it would be easier to compare two assets if each of their contexts consists of a subset of a lexicon of “context tags” than if each asset’s context consists of a paragraph of free-form text. Similarly, as size of this context tag lexicon increases, comparing contexts becomes more cumbersome. If every web asset is tagged with its top five most frequent words, then the total context tag set across all web assets could quickly become unmanageable as the number of web assets being tagged grows.
In order to create a set of context tags that could be used to contextualize web assets, web assets may be examined from several perspectives: spatio-visually (layout, colors, design) as a screenshot, as structured code (HTML, CSS), and as a document consisting of written language. A convolutional neural network like Eyeballer can be used to generate tags for a webpage based solely on screenshots of its fully-rendered state. This approach is useful for tags that represent complex categories that nevertheless possess distinctive visual elements, such as the category of “blog” web pages or the category of “old-looking” web pages.
However, it requires significant amounts of labeled data to be precise enough for production, and existing publicly available datasets are not sufficiently large.
An example of code-based context tag generation would be examining a web page’s HTML for an <input> tag with type “password” in order to determine if the page has a login feature. Finally, for text-based tags, natural language processing techniques such as bag-of-words frequency analysis can be applied.
For web asset contexts, one area to explore further is combining spatio-visual information and semantic information to generate tags. A simple bag-of-words frequency analysis may not be very effective on web pages because word frequencies on web pages exhibit sparsity. While important words may show up with high-frequency in traditional text (books, articles, etc.), important words might show up only once or twice on a web page if much of their importance is conveyed via positioning or styling. For example, an “About” page for a company might only display the word “About” once, but “About” would probably appear in large size font at the top of the page, possibly with extra embellishments and separated from other text.
Eyeballer
One proposed approach to providing context for web assets is Eyeballer, which uses a convolutional neural network to categorize web page screenshots. It is open-sourced, and its creators (“BishopFox”) have trained and tested it on a set of ~13,000 webpage screenshots. Its architecture consists of a MobileNet layer pre-trained on the popular ImageNet dataset and then a fine-tuning layer consisting of global average pooling and dense neural network layers for classification.
It uses MobileNet as opposed to other image models built for transfer learning because MobileNet is lightweight relative to its peers. It is pre-trained to determine if a web page can be identified with a subset of the following tags: “homepage,” “custom 404,” “login,” and “old-looking.” On a set of approximately 2,000 images (manually labeled by BishopFox), the network exhibits an all-or-nothing accuracy of 73.77%. For specific labels, the following precision and recall percentages were observed.
LabelCustom404LoginHomepageOld-lookingPrecision95.38%82.04%76.61%86.82%Recall66.19%89.89%94.16%66.32%
The convolutional neural network approach should be well-suited towards identifying high-level visual context such as whether a page is a blog or a homepage. However, in its current state Eyeballer may not be accurate enough for context generation in production.
Since it is unclear how complex categories such as that of a “homepage” could be identified from a code or text-based perspective, I turn to how Eyeballer could be improved.
In particular, there are four avenues for improvement: increased data, hyperparameter tuning, improving the model’s ability to extract features specific to web pages, and more precise label choice. Firstly, the most obvious way to improve this model would be to increase the training data set. However, this can be expensive. The default threshold at which a confidence score is interpreted as predicting a label is 50%. Raising this threshold to 90% improved precision for the “old-looking” label to 94.21% but lowered its recall to 39.58%. In general, adjusting this threshold means trading recall for precision.
Secondly, the specific architecture of Eyeballer could possibly be improved in future versions to better learn to extract web page features. The current training paradigm begins with a neural network pretrained on ImageNet (a large corpus of labeled images of objects) and then trains a fine-tuning layer on top of it. The underlying pre-trained neural network is not trained, however, to extract different features of a webpage (such as navigation bars or input fields) but is rather trained to identify more general lines and shapes. Due to Eyeballer’s global average pooling layer, which is immediately applied to the output of MobileNet, Eyeballer does not have a layer of convolutions that learn to extract features specific to web pages such as navigation bars or comment sections.
Exploring additional convolutional feature extraction layers (in conjunction with additional training data) could engender nontrivial improvements. In addition to training these additional layers with the existing dataset provided by BishopFox, transfer learning could also be applied. By temporarily replacing the Eyeballer classification layer with another classification layer that outputs whether a webpage contains common web page elements such as a navigation bar or comment section, and training this modified neural network on a dataset of web screenshots annotated with whether they include each of these web page elements, the intermediary convolution layers might learn to extract these web page elements.
Finally, label choice might help to improve the model. For example, it might be the case that the model is struggling to achieve a >90% precision for homepage classification because the visual particulars of homepages are so varied. 8,000 training screenshots may not be enough to capture this diversity sufficiently. However, note that homepages are of interest primarily because they typically link to many other pages, which may themselves possess sensitive assets, and then note that these links usually appear in some form of a navigation bar. Therefore, it might be just as useful to label web assets by whether or not they have a navigation bar as it is to label them by whether or not they are a homepage. Since navigation bars are less varied in form than homepages (they usually are at the tops of pages, display rows of words or phrases, etc.) a convolutional neural network may be able to learn to identify them more easily than they could learn to identify homepages in general.
HTML and CSS-informed keyword extraction
A bag-of-words approach can be applied to a webpage pretty simply. Firstly, the domain in question is visited. Then, the response’s HTML is parsed for all words that are not HTML tags or arguments. This will yield a multiset of words that can be cleaned with standard natural language processing techniques such as tokenization, removing stop words, removing punctuation, only preserving adjectives and nouns, generating n-grams, and lemmatization. This cleaning can be achieved easily with a programming package such as NLTK (see this demo code).
Finally, the resultant cleaned set of words forms a multiset, or “bag of words,” that can be further filtered for keyword extraction.
While the bag-of-words approach is useful for keyword extraction in general, the simplest way of determining word importance (frequency analysis) is not particularly well-suited for web page analysis. On a web page, the most important words may only appear infrequently, and visual layout and design is an important means through which information is conveyed. To circumvent this limitation, words can be tagged with features that signify their importance beyond frequency, and this expanded feature set can be used to determine relative word importance.
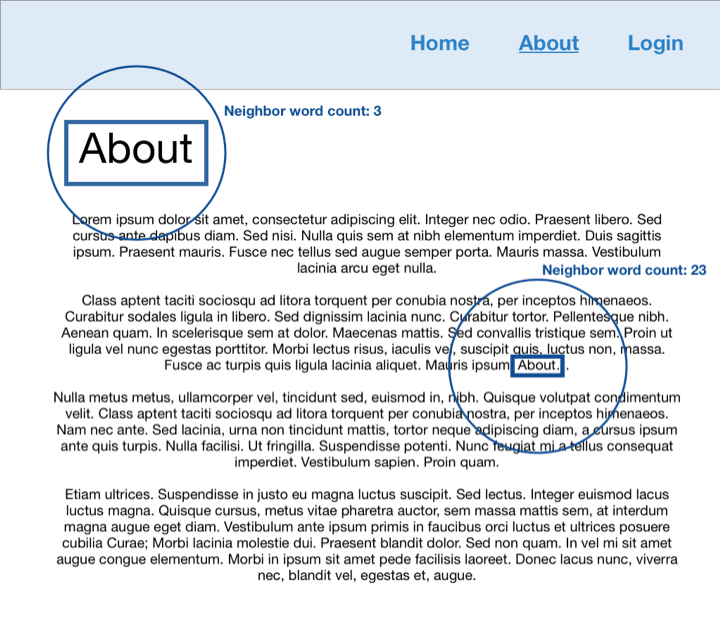
Firstly, words can be analyzed for spatial-visual importance. One heuristic that could be explored is the number of words that exist within a circle around a particular instance of a word. For example, suppose the word “About” appears on a web page twice. Then, an algorithm can be employed to take as input a screenshot of the webpage in question and annotate each instance of a word with a dot at its center. For each instance of the word “About,” a second algorithm can count the number of words (represented by dots) within a circle of X radius. If there are very few neighboring words for one of the instances of “About,” it could be concluded that this instance of “About” is a title and that furthermore this web page is an “About” page.
Practically, this approach is limited by the fact that not all “About” pages will display the word “About” as a title. They might instead display the words “Our Story” or “Meet the Owners.” While this approach can look for these synonym titles as well, it will not exhaustively identify all possible titles for an “About” page. In other words, the precision would be high (if a page has “About” or “Our Story” as a title, then it most likely is an “About” page) but recall might be lower (if an “About” page has a different title, then it might not be properly identified).
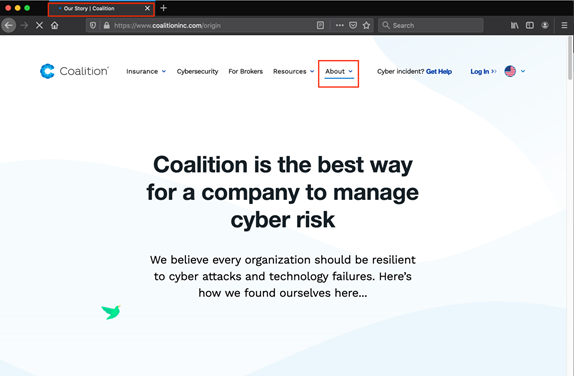
Secondly, words can be analyzed via a web page’s HTML. For example, a word is probably more important if it is included within the <title> in a web page’s <head>. On the “About” page for Coalition, there is no generic title within the body of the page that strongly indicates that the page is an “About” page.
However, the <title> (top-left) includes “Our Story,” and the selected navbar element (top-middle) includes “About.” An initial list of tags to mark as signifying higher importance could be: <h1> through <h6>, <title>, <strong>, <summary>, <th>, <button>, and <a>.
Thirdly, words can be analyzed via their styling in CSS. If the size of a word according to its styling is in the upper quartile of word sizes on a web page, then this word is more likely to be important on that page. Similarly, bold font, italics, underlining, and a font that differs from that of most words on the page all indicate that a word might be of particular importance.
Finally, words can be analyzed to determine whether or not they are displayed in navigation bars or side bars. A convolutional neural network can be used to identify and annotate sidebars and navigation bars in a screenshot of a webpage. A second neural network can be used to annotate words in a screenshot of a webpage. These two annotation sets can be intersected to determine if a particular word is displayed in a sidebar or navigation bar. To handle the situation where sidebars or navigation bars are dropdowns, or otherwise only appear on hover or click of a particular button, the screenshotting algorithm can take a screenshot after hovering and clicking on every <button> and <a> that does not have an “href” or “form” parameter.
These analyses will enable more robust weighting of word importance on web pages. Once these features are collected, then they can be used to extract key words. Initially, a heuristic could be applied to generate a single “word importance” from these features. Eventually, a statistical model such as a logistic regression could be trained to predict if a word is important based on these features. If all “important” words are labeled as keywords for a web page, however, a dimensionality issue could arise: If web pages’ keywords are too diverse, it will be hard to compare them. One fix to this problem would be to only extract key words that are also contained in some external lexicon. To make this fix less brittle, synonyms and close linguistic cousins of words in this external lexicon could also be extracted as keywords. For example, if the most important word on a web page is “money” but only “financial” exists in the lexicon, then there would still be a match, and “money” would be annotated with a note that it was matched because it is a close linguistic cousin of “financial.”
HTML analysis
Tags can be generated by traditional HTML analysis as well. For example, a login feature on a web page probably contains an <input> with a type or placeholder that includes “username,” “email,” “password,” or “pin.” If a web asset points to a homepage, then the login feature might be hidden on a web page that can be navigated to via a link on the homepage. An algorithm can load and analyze the homepage, visit all of its links, and then analyze all of the HTML returned from those links of the same domain or subdomain, in order to find the login feature if it exists (see this demo code)
There are really two approaches to creating context tags for web pages: analysis (i.e. HTML parsing) and machine learning. Simpler tasks such as determining if a page has a login feature should be handled with an analytical approach, as this provides stronger performance guarantees. However, more complex tasks such as determining if a page is a homepage practically require a machine learning approach. Complex tasks like this can involve machine learning applied to either screenshots or HTML. While the former seems simpler, the latter actually sometimes makes more sense. HTML is an encoding of the visual aspects of a webpage, and so by training models on HTML, these models can largely avoid the task of having to create internal representations of websites from screenshots. Instead, they start with structured representation of screenshots, reducing the complexity of the learning task.
By creating a set of context tags through a variety of means including screenshot analysis with deep learning, text analysis with natural language processing, and code analysis, structured representations of websites can be constructed that enable their categorization and comparison. Since context tags will largely be qualitative in nature (i.e. nouns such as “blog” or adjectives such as “old-looking”), they will have to be given a heuristic ordering by a domain expert.
Coalition recently launched Coalition Control — an integrated platform that allows organizations to take control of their cyber risk. Sign up with just your email address today and start controlling your risk.





