
Improving Cyber Underwriting with Active Learning

The core requirement of any risk-taking insurance platform is the ability to accurately and consistently score the risk of a potential insurance policy. Despite the buzz about artificial intelligence replacing traditional insurance underwriting, we believe best-in-class underwriting in cyber is achieved by combining human expertise with algorithmic decision-making. Active Learning is a subset of machine learning where the algorithm is able to "phone a friend", game-show style. The best active learning systems leverage humans by quickly integrating expert judgement back into the algorithm, as well as querying humans only when human judgement is truly needed. Don't phone a friend on the easy game show question!
Setting up an active learning framework
At Coalition, we started automated underwriting by using our best human judgement to create heuristics on what types of quotes we want a human to review.
For example, we may decide that any company involved in cryptocurrency technology should receive a second look from our cybersecurity team.
We'll call this decision criteria sr, for secondary review. Given quote information x, sr(x) returns true if the quote requires a human review.
For companies that don't need a review, we apply automated production pricing model f on x to produce f(x) = price_model. For companies that do need a review, our cybersecurity experts work with our insurance team to price the risk, returning price_human.
Finally, we may collect feedback on our pricing from our producers and broker partners. If an automatically-priced quote price_model is outside of some acceptable price range, it may be escalated back to our team, and kicked to a human reviewer, resulting in price_human.
This flow can be represented by the following diagram:
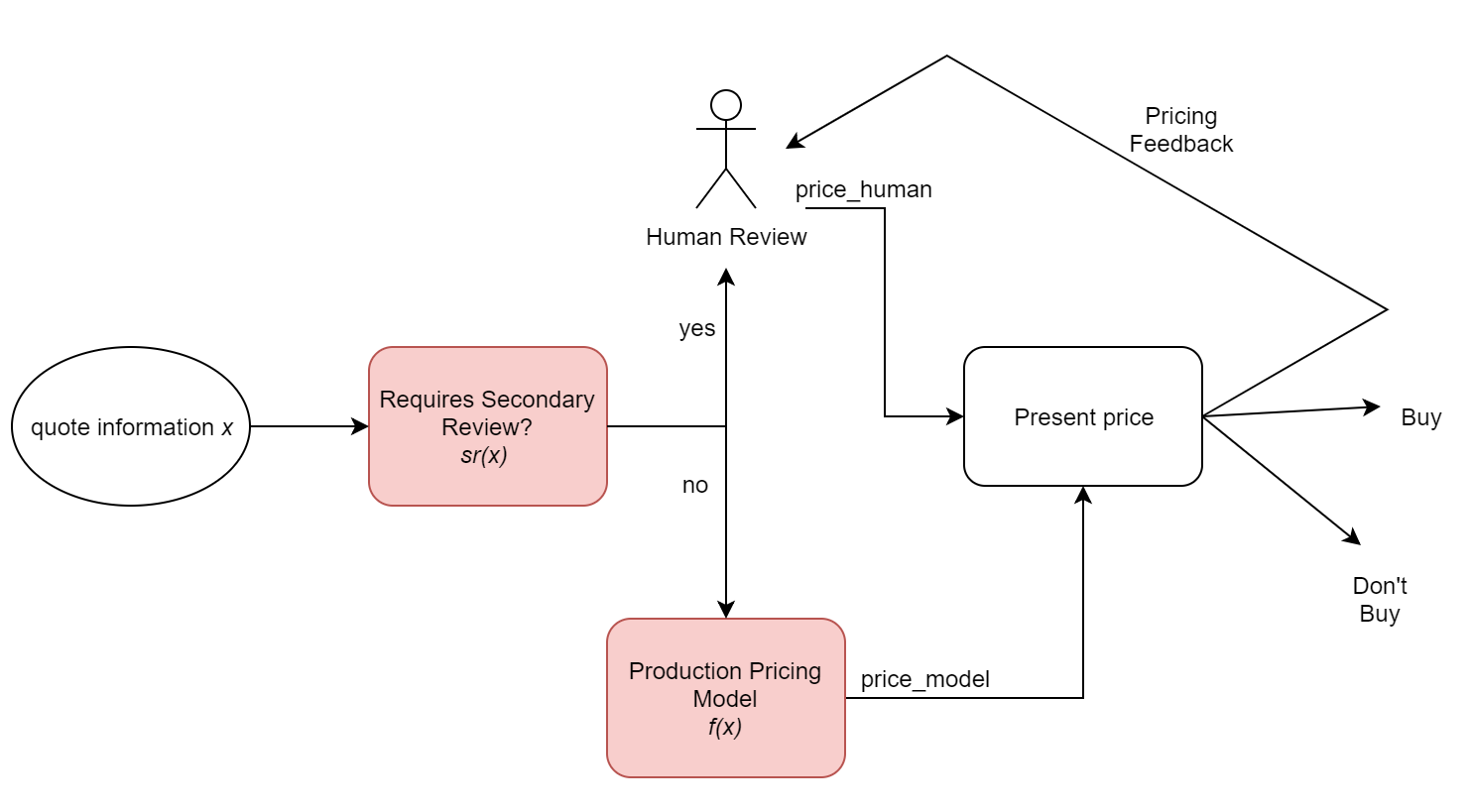
With this setup, we can go about improving both our our production pricing model f(x) as well as secondary review criteria function sr(x).
Feeding the pricing machine
Our human reviewers bring decades of cybersecurity and insurance expertise, so every time they price a quote, we obtain a sharper image of the risk level and resulting desired behavior of the pricing model - sort of like how buying a vowel on Wheel of Fortune gives you great information on how the phrase will turn out!
I'd like to solve the puzzle!
By training a predictive model on the expert's pricing adjustments, we can add this knowledge back into the production pricing model.
For example, let’s examine the pricing of our production model vs our new trained model for a given feature x_1.
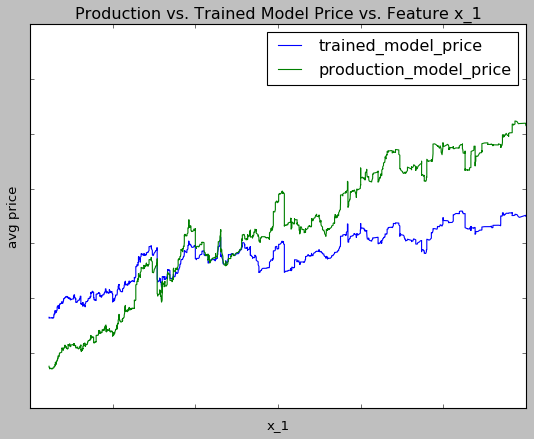
This graph suggests that our experts recommend a higher price than our production pricing model for low values of x_1, and recommend a lower price than our production pricing model for high values of x_1. Based on this observation, we should consider adjusting the role x_1 plays in our production pricing model.
Scale: Improving our review criteria
As we collect more pricing feedback, we can create a data-informed opinion on what types of quotes require manual review. By finding quote characteristics that correlate to agreement between our human experts and the production pricing model, we can adjust pricing, and then exclude these types of quotes from human review going forward.
For example, let's assume that the secondary review logic is a union of ten conditions. By running our most recent production pricing model against all historical quotes, we can graph each condition vs. the magnitude of change the human reviewers make on these types of quotes:
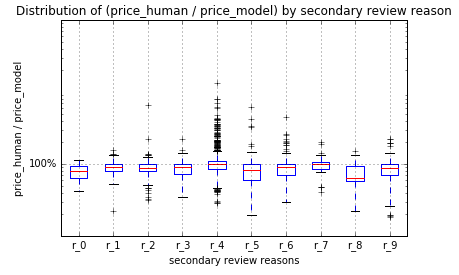
Here, we see that human pricing on quotes escalated for reasons r_0, r_1, and r_7 have relatively small pricing adjustments. In particular, the adjustment for prices in criteria r_0 are below 100%, so we should consider a slight price discount for these types of quotes. The adjustment for prices in criteria r_1 and r_7 are both minimal and centered around 100% (no price adjustment), suggesting that we can safely let the production model score these quotes. This will reduce the overall burden on our human team.
Conversely, our human experts are making large adjustments for quotes that triggered reason r_4, suggesting that we should dig deeper on what factors are driving this disparate pricing for these particular quotes.
Finally, if we find a new group of quotes that have human pricing with large discrepancies from our model pricing, we can propose a new secondary review condition r_10, to both make sure we are pricing these quotes effectively in the short-term, and collecting useful human pricing data so that we can go back to scoring these quotes algorithmically in the long-term.
Conclusion and next steps
We believe that the best underwriting comes from combining cybersecurity experts and algorithmic decision-making. Our active learning framework allows us to continuously improve our model while also reducing the review burden on our human team. So what's next?
First, we want to increase the amount of data we collect during the underwriting process, capturing, as much as possible, each applicant's cyber risk footprint.
Second, many of the above model-improvement processes can be automated. Nothing is stopping us from launching a new risk model every day of the week!
Finally, we pride ourselves in working to protect our insureds by offering cybersecurity recommendations and apps. As we collect more data, we can build models around what types of actions are most likely to prevent an insurer from suffering a breach.
If these problems sound interesting to you, let us know. We're hiring.
Related blog posts

Blog
3 New Ways You Can Get to Bind Faster
To help you move from submission to bind with less friction, Coalition has introduced three new enhancements in the Broker Platform.


Blog
Generate Renewal Quotes in Minutes with New Self-Serve Tools
With Coalition’s Self-Serve Renewal Tools, you can update applications and generate custom quotes directly in the Broker Platform.


Blog
Voices in the Cyber Crowd: Key Takeaways from NetDiligence Miami
Coalition recently caught up with cyber insurance industry leaders at NetDiligence’s Cyber Risk Summit in Miami.
