
Move fast and don’t break things: Coalition’s risk backtesting


Coalition is a technology (and data) company at heart and an insurance company by trade. Our engineering, data, and product teams are constantly innovating. This is a brief analysis of how the data science team uses rapid backtesting to update our decisioning systems while maintaining their integrity.
On any given day, Coalition’s systems assess and underwrite billions of dollars of potential cyber risk exposure for companies across the United States and Canada. One core function of the company is to achieve the seemingly incongruous dual objectives of moving fast — updating our systems to combat the ever-changing nature of cyber risk — while maintaining absolute integrity of our risk and pricing systems and understanding exactly how a change will affect risk assessments (don’t break things).
One key contribution to our ability to confidently roll out improvements is our ability to backtest all risk changes against historical data, using the same code that will be used on a go-forward basis in production. This post dives into the system we built to achieve our current backtesting capabilities. By focusing on a consistent and reproducible workflow, we enabled ourselves to continually evolve our models with a quick feedback loop, reducing the risk of individual deployments while also setting us up for the rapidly evolving cyber risk landscape.
Getting it setup
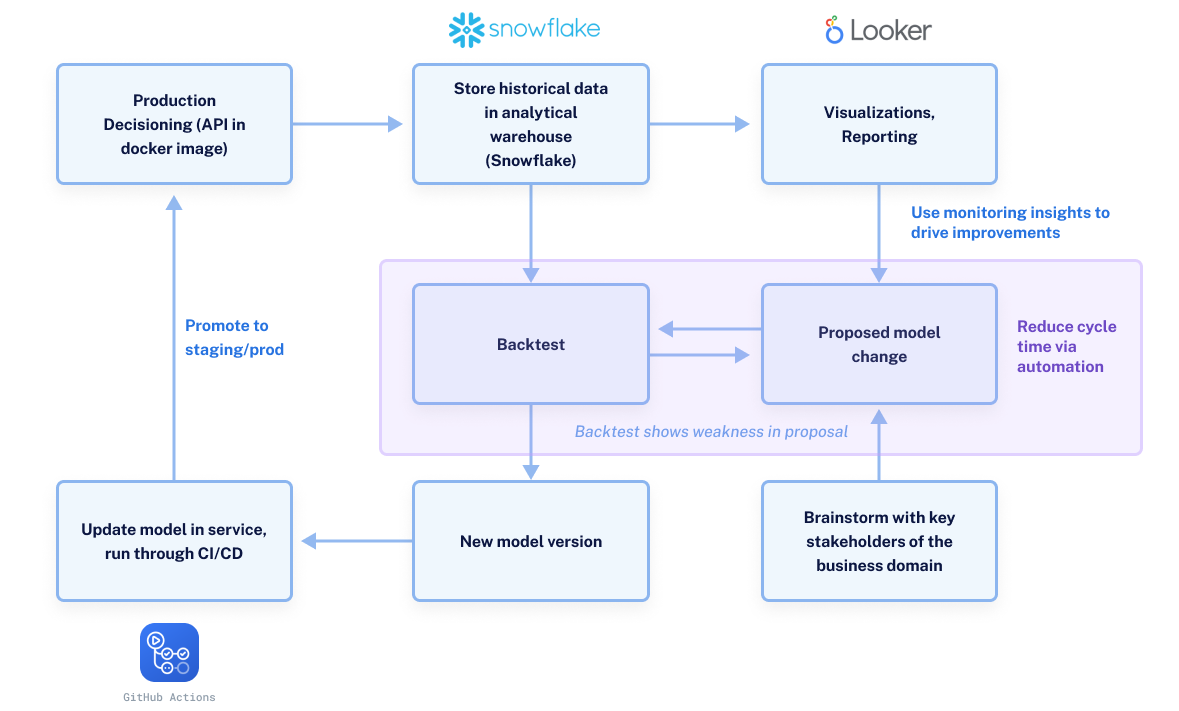
Accessible and accurate records are a prerequisite for running successful candidate models. As we run our models in production, we collect all inputs and outputs and store them in an analytical table in Snowflake. This means that any time in the future, we can run a new model version on our past historical data to play out what would have happened if we had deployed the candidate model during that time. By directly predicting against production inputs, we can eliminate a whole type of discrepancy in our analysis that might occur due to mismatches in production and offline data.
Most people who work with data are well versed in the importance of having a good data collection process. We’ve observed (anecdotally) that data analytics workflows suffer from a lot of configuration issues. Making sure that we have a consistent computing environment is a critical component for the reliability and reproducibility of any analysis, and backtesting is no exception. It’s simply too easy to download a dataset locally and start running a Jupyter Notebook to analyze, but this approach often leaves many implicit facets of configuration:
What are the dependencies and versions needed to run this code and get the same result?
Where did the data come from, and how do I access it?
Was the data modified from the source when retrieved?
Did I do something on a different operating system that will cause problems if I try to repeat it on another?
Will I run out of memory if I try to run this on my laptop? Will the process finish in a reasonable amount of time?
Running the backtest
Once we have the data collected, and a consistent environment provisioned, doing the actual computation to backtest our proposed model becomes trivial. In the simple case, we run a query against Snowflake and evaluate the model on the data. We take care to ensure that the data pull for the backtesting data is explicit in the workflow. This clarifies exactly the scope of the backtest and allows it to be repeated in the future with minor modification. If we need to reproduce the runs later we can, even if somebody else is the one redoing it. Depending on the nature of the change we’re making, the proper analysis might be simple or we could spend a decent amount of time pouring over graphs and making custom analyses. Regardless of the changes, there’s a handful of metrics we generally always want to see. They boil down to who will this change impact, what’s the magnitude of the changes, and what’s the cause of the changes we’re seeing?
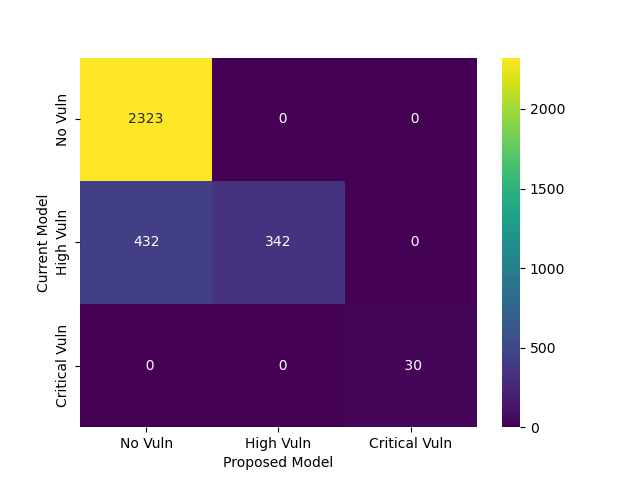
One of our models, which decides if a policy applicant should undergo additional scrutiny by a security expert, takes advantage of Coalition's internet scanning platform. Since the implementation is a rules engine, we have exact information on the reasons explaining why the model thinks a second opinion is necessary. As a result, a great visualization for us to see model changes is how the reasons for each policy changed from one iteration to the next.
We like to visualize these reasons as a confusion matrix that simply compares the current model to the proposed model. By looking at the reasons, we can see that when we modified a rule to ignore certain false positives of a bad security vulnerability, the result is a few hundred policies removed from our security review queue over the backtest period. At the same time, we have the reassurance that no quotes with a really bad vulnerability are inadvertently let through. Since we wanted to decrease strain on our security team, we were happy with this result and decided to go forward with it.
Reason changes of proposed model
Promotion to production
Being able to see model changes offline hypothetically is one thing, but we aren’t gaining much ground until the updates can be pushed to live traffic in production. One simplifying approach to maintain consistency in both the analytical and production environments is to use a common library containing only the model and stateless prediction functions. We can store the model library and any required binary artifacts in an internal package repository. Then, when we use the model, we simply install it as we would any other dependency when building the model service’s docker image. During offline use (backtesting and experimentation) we can install the library as a dependency of the backtesting framework. If we need multiple versions of the model for comparison, any environment management solution will work just fine, but we’ve used both Docker and Conda environments to achieve analysis of multiple model versions.
As a part of the continuous integration of our model service, we run this backtest on any significant model changes. Once we’re happy with the results, we bump the model library’s version in our service’s dependencies and rebuild its docker image. Deployment to our development environment is done automatically via our CI pipelines, and we run a few synthetic tests in that environment before pushing the changes to staging and production. As the new model gets its reps on production data, we will continue to monitor its performance until we decide to start the next improvement cycle.
Conclusion
Coalition’s position as a relatively young company in a rapidly changing cyber insurance market requires us to be nimble in our decision-making systems. At the same time, the consequences of letting a broken model in production can hamper the growth and health of our book. We can have our cake and eat it too, by shamelessly plucking moves from the playbook of continuous delivery and our DevOps colleagues, and applying them directly to our data-driven systems. Not only can we make changes faster, but the process that enables us to do that also brings reproducibility and reduced risk of model changes. In an industry where being slow to react is risky, you have to be quick. Just don’t break things.
If these types of challenges sound interesting, or you’d like to learn more about data science at Coalition, visit our careers page for more information and open opportunities.
Related blog posts

Blog
Bridging the Cyber Insurance Gap Between Brokers and SMEs
Coalition UK research reveals a gap between specialist cyber insurance take-up by SME decision makers and broker impact on outcomes.


Blog
Beyond Capacity: How Coalition Re is Building the Future of Cyber Stability
Coalition Re harnesses the full power of Coalition’s cyber intelligence to give reinsurance cedants an unprecedented view across the entire digital ecosystem.


Blog
New Privacy Risk Insights to Help Navigate Wrongful Collection
As wrongful collection claims rise, Active Privacy Protection provides businesses with visibility to privacy-related exposures.
